EMNLP 2022 (The Conference on Empirical Methods in Natural Language Processing)是自然语言处理领域的顶级国际会议,由国际语言学会SIGDAT小组在世界范围内每年召开一次,与ACL、NAACL组成公认的NLP领域的三大顶会,代表当前最前沿的自然语言处理技术的进展。今年的EMNLP将于2022年12月7日至11日以混合形式在阿联酋阿布扎比 (Abu Dhabi) 举行。其中,数据智能应用部AI-Lab的三篇文章被Findings of the Association for Computational Linguistics: EMNLP 2022收录。
这三篇论文涵盖了文本匹配、知识表示、预训练语言模型等自然语言处理的重要研究领域,解决了挑战性的难题并获得了国际同行的认可。自然语言处理作为人工智能中的重要技术,已成为度小满信贷风控等各类业务的重要支撑。这些模型的使用可以高效地提升文本与知识特征表示的准确性,在保障相关业务的稳健发展上起到了十分重要的作用。
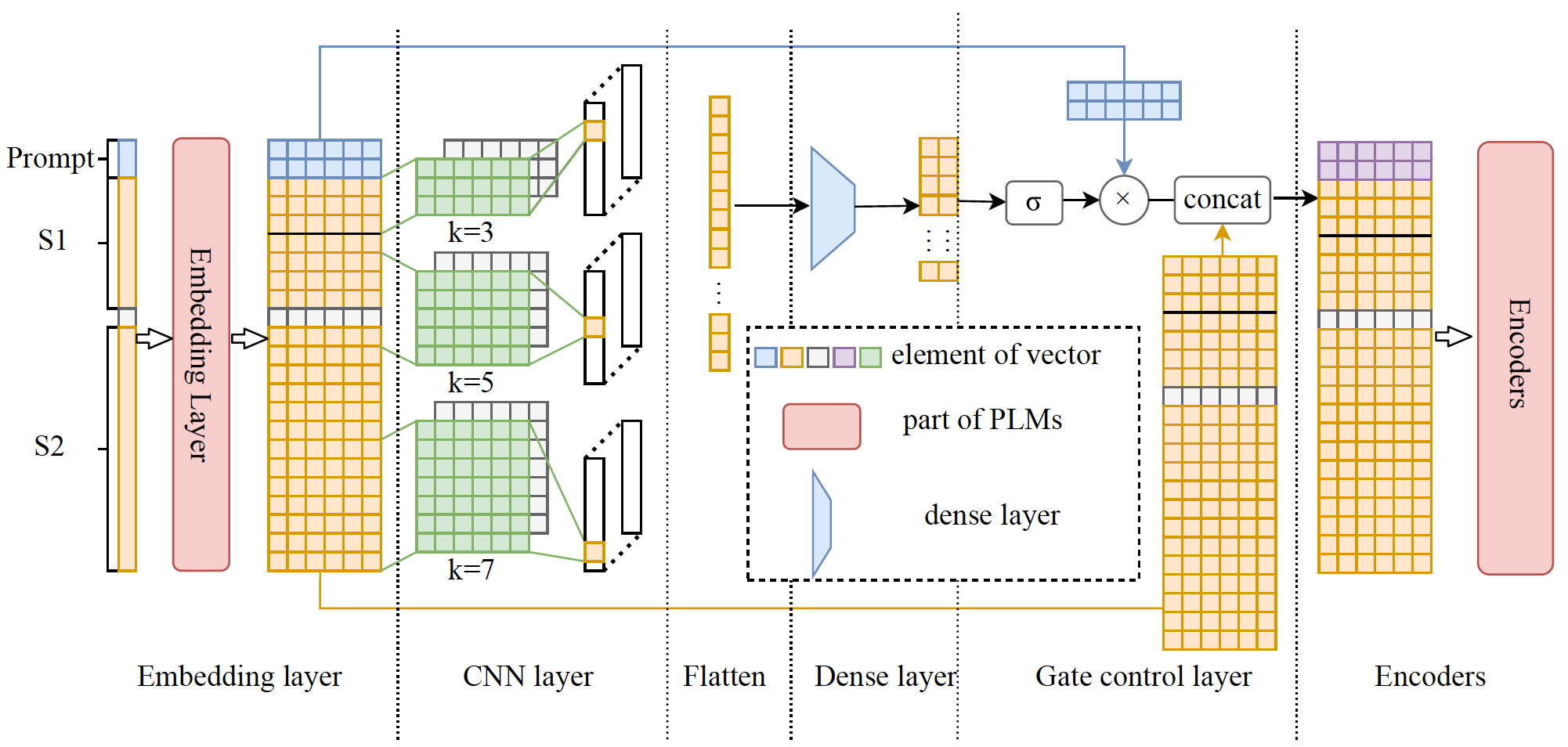
论文1 用于文本匹配的实例引导提示学习算法
Instance-Guided Prompt Learning for Few-Shot Text Matching
简介:少样本文本匹配是自然语言处理中一种重要的基础任务,它主要用于在少量样本情况下确定两段文本的语义是否相同。其主要设计模式是将文本匹配重新转换为预训练任务,并在所有实例中使用统一的提示信息,但这种模式并没有考虑到提示信息和实例之间的联系。所以我们认为实例和提示之间动态增强的相关性是必要的,因为单一的固定的提示信息并不能充分适应推理中的所有不同实例。为此我们提出了IGATE模型用于少样本的文本匹配,它是一种新颖的且可以即插即用的提示学习方法。IGATE模型中的gate机制应用于嵌入和PLM编码器之间,利用实例的语义来调节gate对提示信息的影响。实验结果表明,IGATE在MRPC和QQP数据集上实现了SOTA性能并优于之前最好的基线模型。
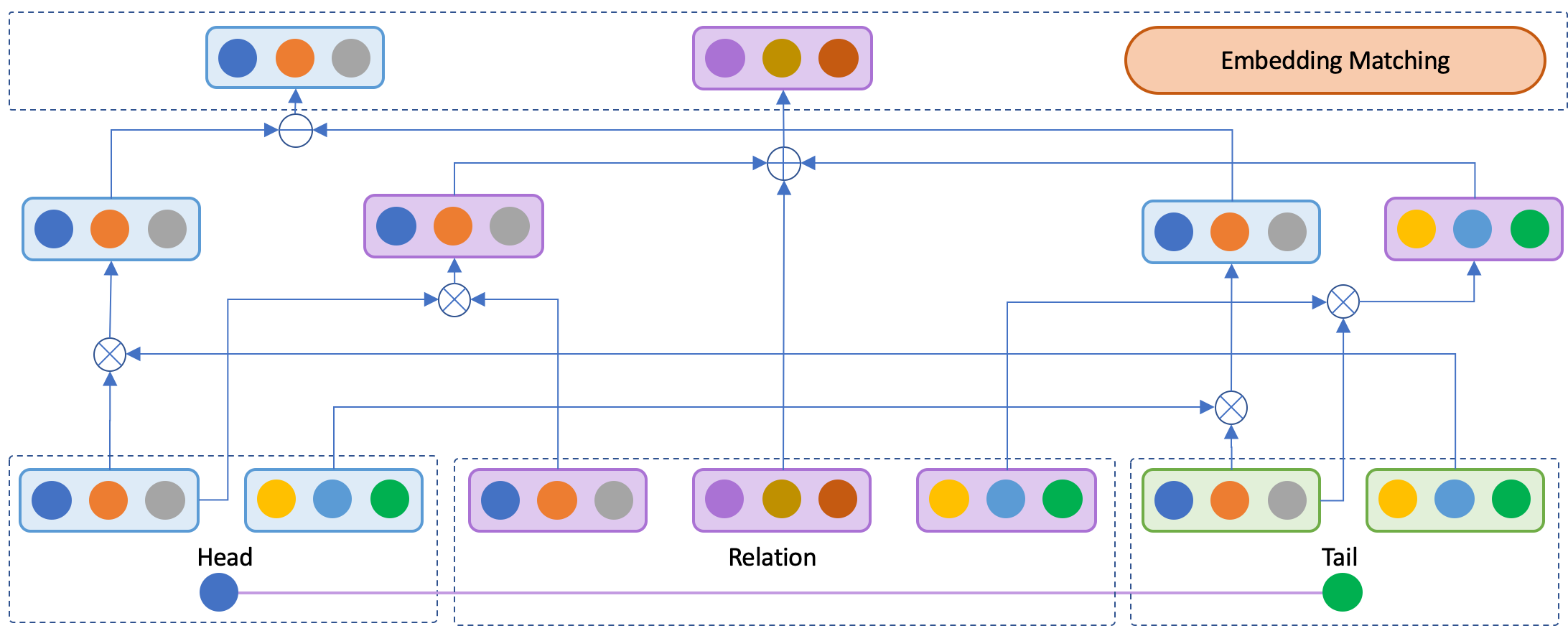
论文2 用于转换形式知识表示的关系嵌入算法
Transition-based Knowledge Graph Embedding with Synthetic Relation
简介:在自然语言处理任务中如何将知识的关联关系引入到模型中是一项具有挑战性的任务,同时也是KG其他下游任务的基础,如知识问答、知识匹配和知识推理等。虽然预训练模型中已经暗涵各类常识知识,但是如何显式地表示知识中各元素的关联仍然是十分重要的问题。所以我们提出并构建了新的关系嵌入模式,即构建三段式的关系表示并使得头尾实体的差值近似于该表示。具体来说,三段式合成关系表示中的两部分先分别与头尾实体进行交互并产生新的向量表示,最后将新的三段式关系表示进行合成形成最终的关系嵌入用于模型的训练。实验结果表明,我们的模型可以在相似参数量的情况下有效提升模型性能。
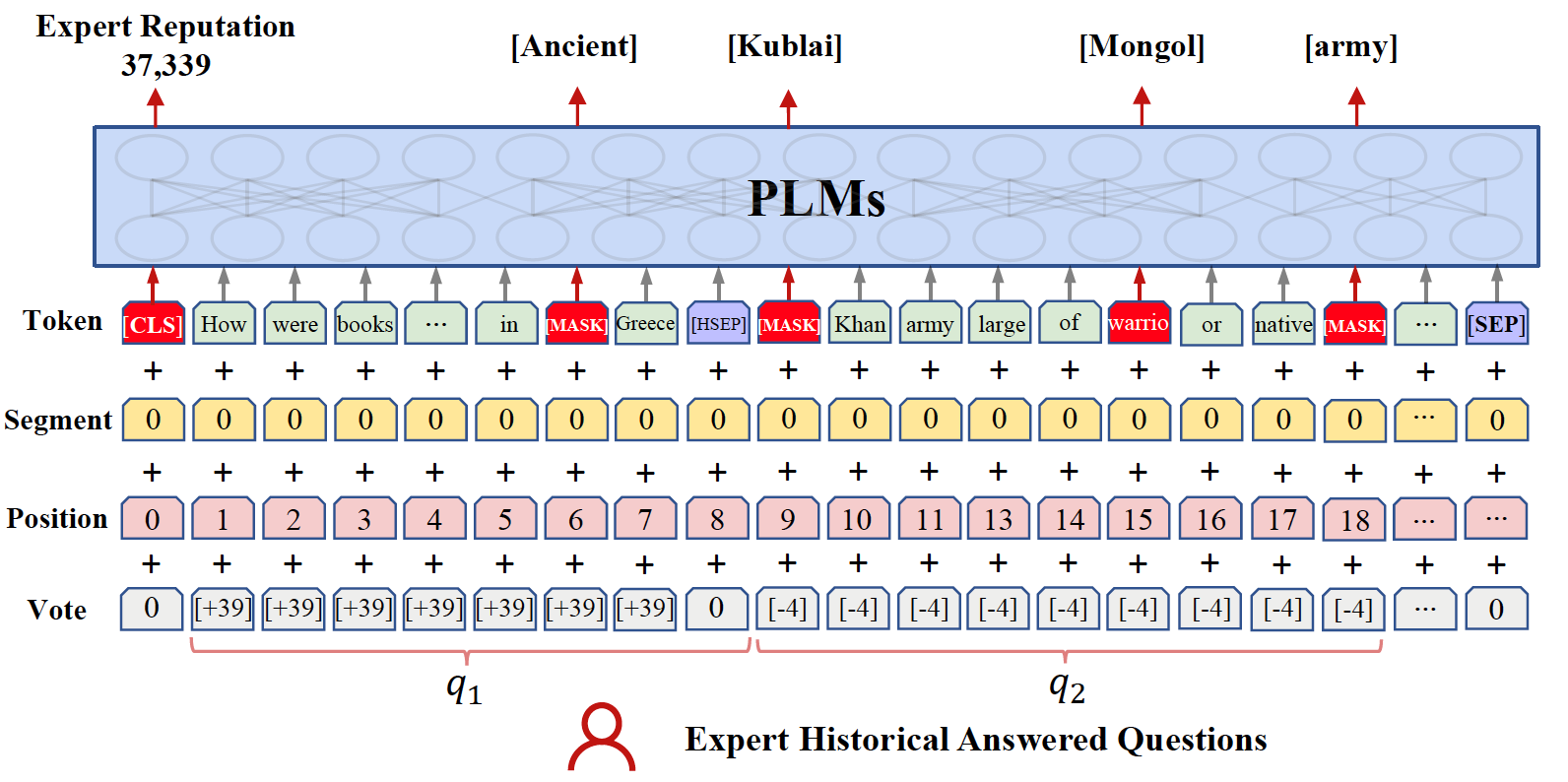
论文3 ExpertPLM:基于预训练语言模型的专家表征模型
ExpertPLM: Pre-training Expert Representation for Expert Finding
本文是在CIKM 2022论文ExperBert的基础上,进一步挖掘如何利用用户的历史文本数据(如搜索内容,回答问题等)对用户进行个性化预训练表征。虽然ExpertBert能够保持预训练与下游任务一致性,然而学到的用户表示局限与某一类下游任务。因此本文提出的Expert PLM与下游任务解耦,旨在利用预训练语言模型PLMs学习更加通用和准确的个性化用户表示。首先将用户的所有历史行为进行聚合,得到该用户的预训练语料。此处我们不仅聚合每条历史行为的文本内容,而且将历史行为的用户特征融合到输入中,来表示该用户对该条记录的影响,以社区问答为例,用户的每个历史回答收到的投票数可以显示出用户回答该问题的能力,在实际业务中,我们将每条历史记录的时间、位置等用户个性化信息,融合到预训练中。这样的预训练语料构造方式相比仅仅利用文本内容,能够体现出当前用户的个性化特性。此外,本文提出一种融合用户画像信息的预训练方式,在掩码预训练模型(MLM)的基础上,同时对用户画像进行预测,这样能够进一步提升模型在预训练过程中学到更多个性化表征。 在社区问答专家发现的下游任务中,ExpertPLM模型能够在多个公开数据集能够显著超越基线算法,实现优异的性能。